ICLR 2026 Oral Paper的解读:MoE 需要更加激进的 Data Scaling 策略
1. 一句话版本
本文就是为了回答标题里的问题:
能否在总参和训练计算量都与 Dense LLM 相同的条件下,训出性能相同的 MoE LLM,从而使得Inference-time的成本降低是一个白白的收益?
回答是:
- 在 fixed total parameters 和 fixed training compute 下,MoE 要达到同规模 Dense 的效果,核心代价不是参数,而是 tokens:它需要消耗大约 倍的 training tokens。这里 是 activation rate,也就是 activated parameters 除以 total parameters。作为交换,MoE 把 per-token FLOPs 降到大约 Dense 的 倍。
- 这笔交换只有在合适的 activation-rate region 里才成立。MoE 并不是越稀疏越好;实验反复显示,真正有效的是一个中等稀疏度区间,大致在 10%-30%,当然随着模型规模的扩大这个区间可能往更稀疏的地方扩张和偏移。
- 当 unique data 有限时,适度 data reuse 可以补上额外的 token demand,并保留大部分 MoE advantage。
结论很简单,但为了验证它,我们付出了极高的实验成本:
一句话的训练 recipe:
Optimized MoE backbone + 合适的 activation rate + 更激进的 token scaling + unique tokens 不够时,适度使用data reuse。
2. Motivation:参数补贴这个 blind spot
文献里常见两种比较方式。
- 一种做法是固定数据和训练设置,然后强调 active-compute efficiency。比如 DeepSeekMoE 16B:它和 DeepSeek 7B Dense 使用同一个 2T-token corpus 训练,论文报告只用了约 40% computation 就达到与 DeepSeek 7B Dense 可比的性能,也能与 LLaMA2 7B 可比;但与此同时,它使用了更大的 total-parameter MoE reservoir [1]。
- 另一种做法是固定 active expert budget 或目标 per-token compute,然后增加 total experts。Kimi K2 的 sparsity scaling ablation 就是这类例子,并且声称越稀疏越好 [3]。
这两种做法都有价值,但它们都没有把 total parameters 锁住。这个变量不是纸面数字,它对应 capacity、HBM footprint、checkpoint size 和最小部署单元;真实系统里,当 batch size 足够大时,几乎所有 experts 都会被激活。因此更硬的问题是:如果 Dense 和 MoE 的 total parameter count 完全相同,training compute 也相同,MoE 还能不能追平甚至超过 Dense?如果可以,就说明收益不只是 parameter 补贴,而是 sparsity 在训练得当时确实能成为架构优势。
3. 资源方程
对 Dense model,论文把 per-token forward computation 近似写成:
这里 表示 per-token forward FLOPs, 表示 total non-embedding parameters, 吸收 sequence length、model width、FFN expansion ratio 等 Dense shape factors。
对一个 total parameter count 相同的 MoE model,有:
这里 表示 activated parameters, 是 activation rate, 吸收 MoE 对应的 shape factors。当 backbone shape 固定后, 和 可以近似看成常数。论文中的完整参数化推导放在中文附录 A,完整 notation 表放在中文附录 D。
如果 表示 consumed training tokens, 表示 total training compute,那么 equal training compute 给出:
整理后得到:
核心置换关系就在这里。
在相同 total parameter count 下,一个 20% activation-rate 的 MoE,每个 token 只付出大约 Dense 五分之一的 FFN-style compute;但如果要消耗同样的 training compute,它就需要处理大约 5 倍 tokens,具体比例会受到 shape-factor correction 的影响。
论文还从另一个方向做了经验验证:在 3B 和 7B 设置下,MoE per-token FLOPs 与 基本接近线性关系(图 1a);相同计算量下的 data 消耗倍数与 基本接近线性关系(图 1b)。
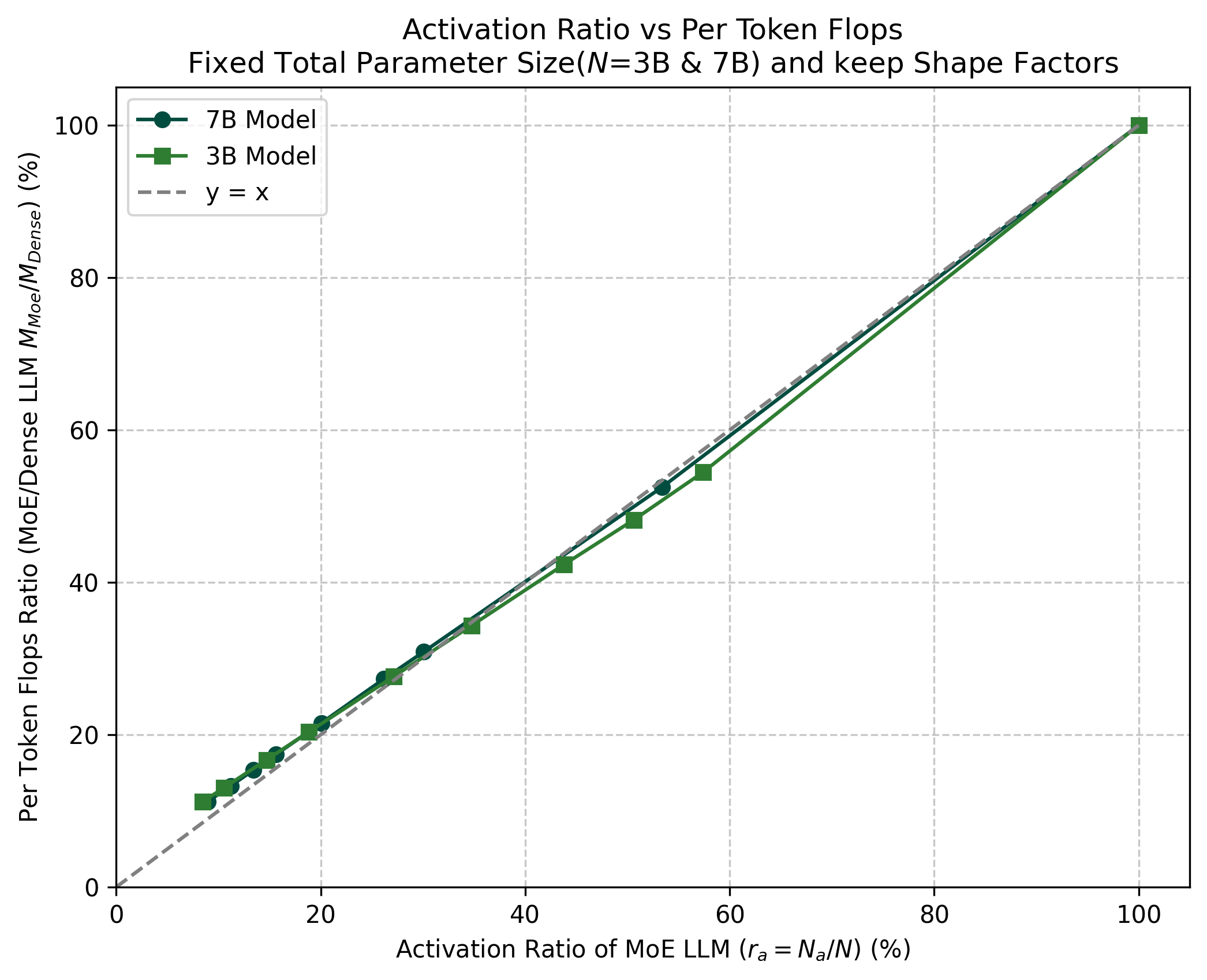
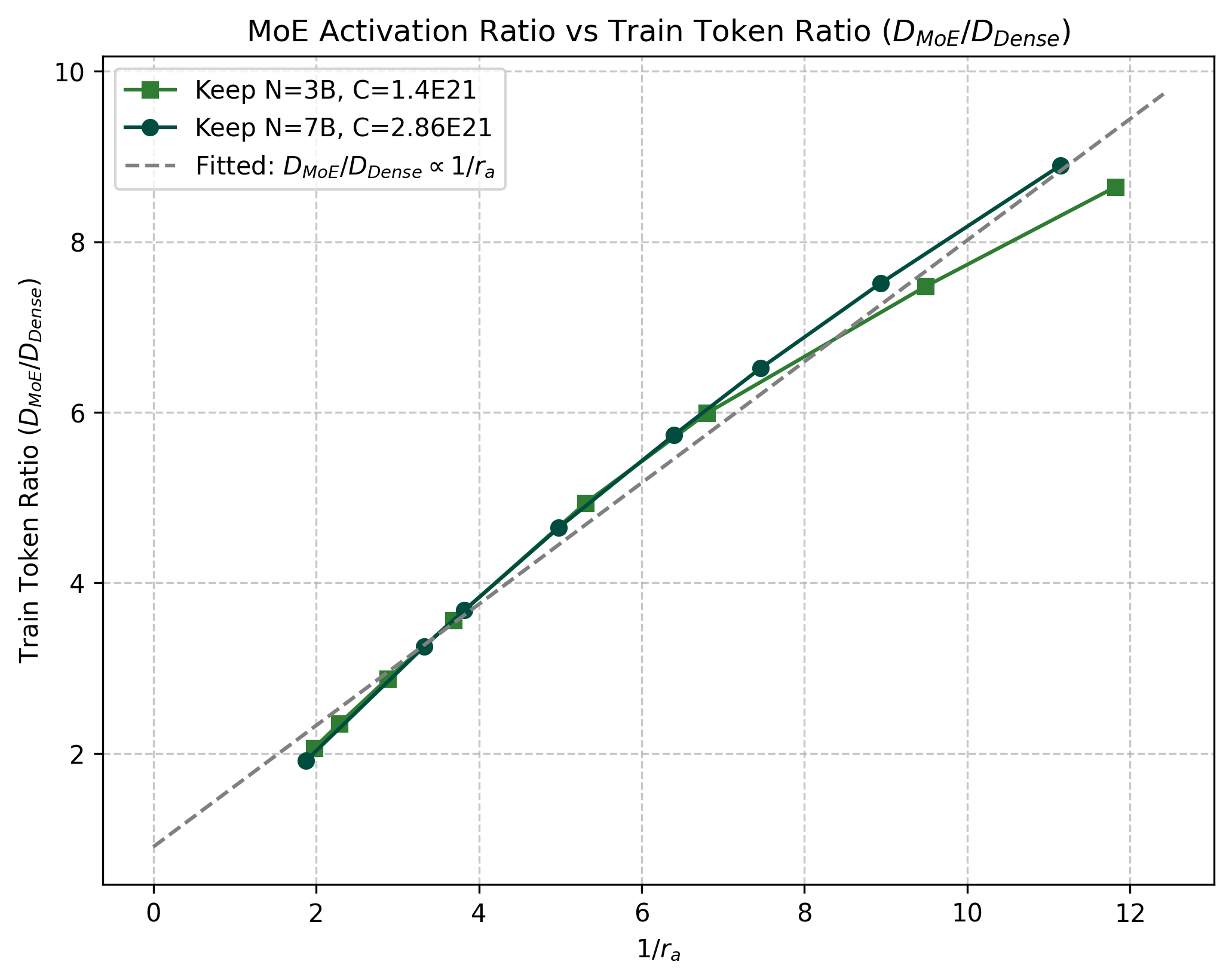
4. 三步方法论
由公式 (2)-(3) 可以看出,在忽略共同的 forward/backward 常数因子后,MoE 的训练算力大致满足 。如果要直接做 MoE 的 compute-optimal sweep,需要同时扫描 architecture、sparsity、total parameters 和 training-token ratio ,维度远高于 Dense scaling law 里常见的 、 两维扫描。在实验资源有限的情况下,本文选择了一条 greedy route:减少模型配置数量,但把每个配置都训到足够高的 ,让比较发生在 sufficiently trained regime,更接近训练 SOTA 模型的生产环境。

图 2. 为博客重绘的三步方法论:先优化并锁定 MoE backbone,再在固定 N 和 C 下搜索 activation rate,最后用 data reuse 在 finite unique data 下做严格比较。
因此本文采用了一种 greedy strategy:先给 MoE 一个足够强的 optimized backbone,再在 fixed total parameters N 和 training compute C 下 sweep ,最后测试 data reuse 的影响。Dense baseline 也不是随便选的,而是采用了 optimal FFN ratio 的策略;因此我们希望比较的是结构上都充分优化过的 Dense 和 MoE。
5. Step 1:Optimize the MoE architecture
MoE 比 Dense 多了很多可调维度。Dense model 基本由宽高比和 FFN ratio 决定;MoE 还要选择 Dense/MoE layer mix、是否使用 shared experts、routing top-K、routed/shared expert sizes、total expert count,以及 global shape ratios。
如果这些因素不先控制住,activation-rate sweep 就可能失去意义。一个坏结果也许只是在说明 MoE backbone 没调好。 因此,architecture search 的作用是先把这个设计空间收窄,得到后续 sweep 所使用的 MoE backbone。
表 1. Step 1 architecture-search 结论表。
| Component | Backbone 中采用的结论 |
|---|---|
| Layer arrangement | 使用 1dense+SE:一个初始 Dense layer,后续为带 shared experts 的 MoE layers。 |
| Gate normalization | 在小模型 ablations 中,normalization 会降低 balance loss。 |
| Top-K routing | 同时避免 K = 1 和过大的 K;条件允许时使用中间范围的 top-K。 |
| Shape ratios | 搜索结果支持的是合理区间,而不是某个唯一最优值:zeta 在 60-120 左右是合理范围,mu 在 20 左右是合理范围。 |
Step 1 的核心是公平。拿 MoE 和 Dense 比之前,论文先把 MoE backbone 调到足够强。这样后面的 activation-rate sweep 问的才是一个更干净的问题:在同样总参预算下,一组结构合理的 MoE 里,什么 activation rate 最有效?kappa_MoE 更稳定有利于资源方程分析,但这只是 secondary benefit。Step 1 的详细实验放在附录 C。
6. Step 2:Search the optimal activation rate
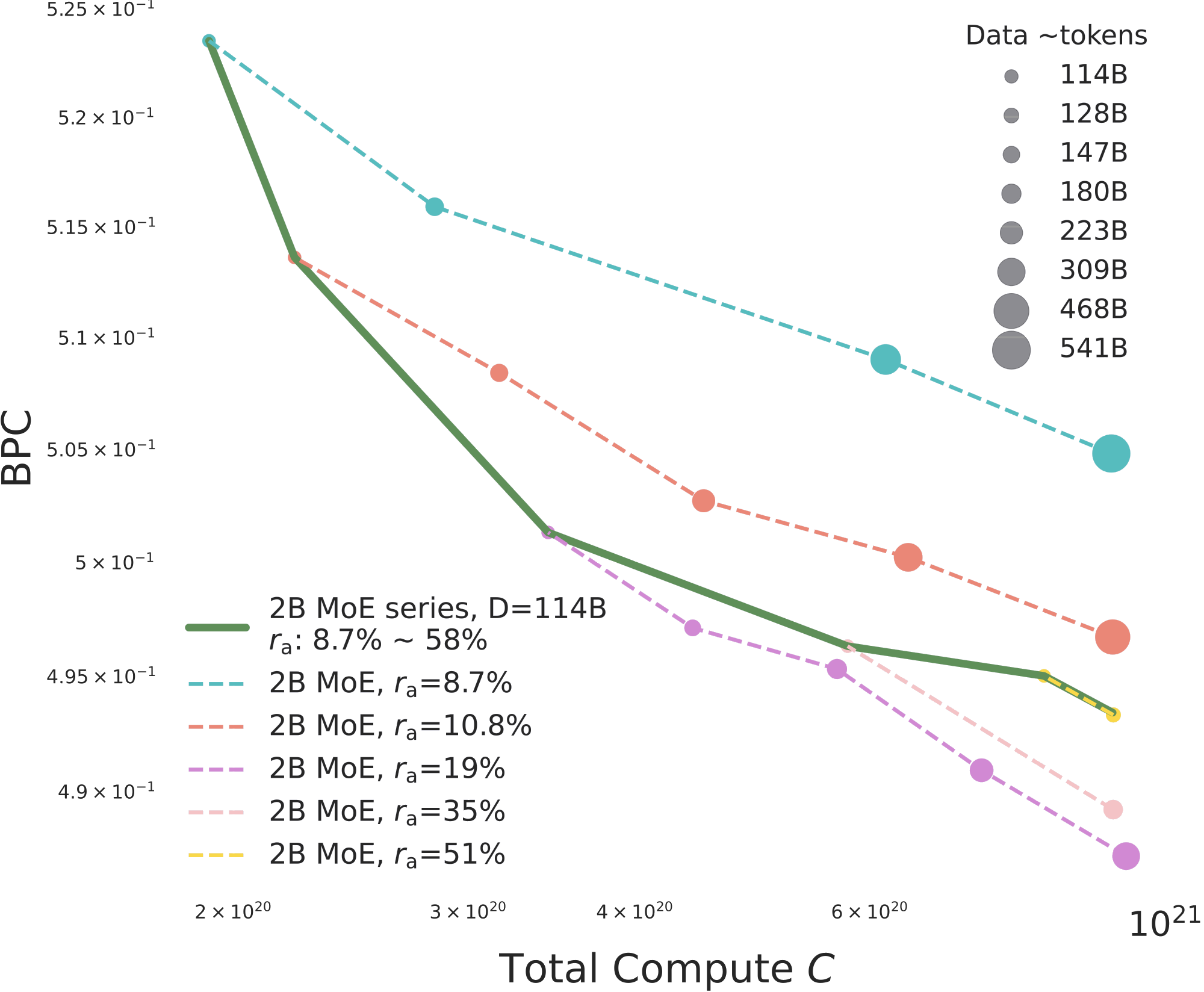
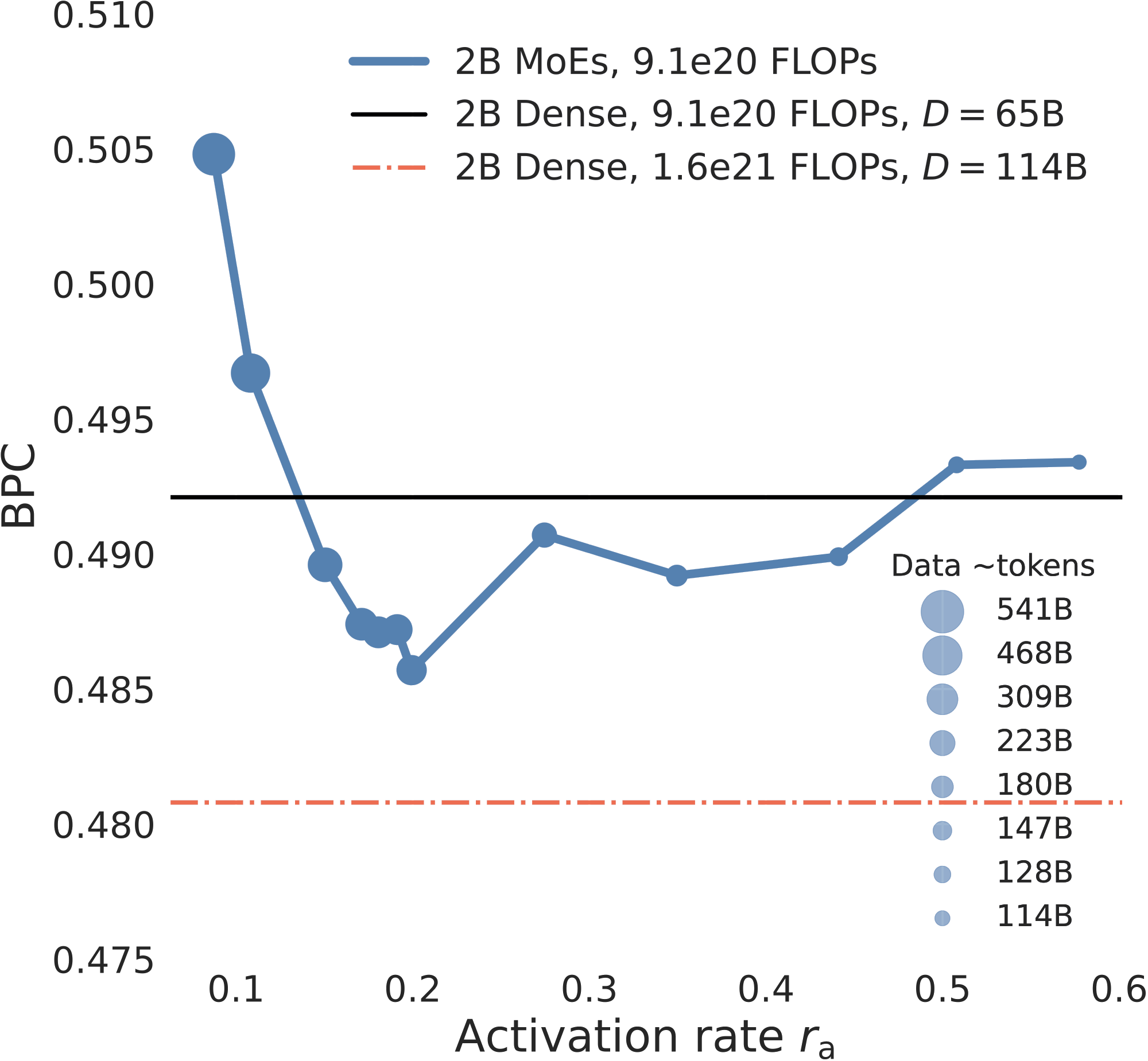
图 3a 的解释是。 横轴是 total training compute,纵轴是 BPC(越低越好)。气泡大小表示 consumed training tokens。每条虚线固定 activation rate 并增加 tokens;沿着这些线往右走,更多 tokens 会稳定地、几乎 log-log linear 地降低 BPC,这符合常见的 data-scaling 直觉。绿色实线则固定 data budget 为 D = 114B,从 sparse 到 dense 改变 。这把两种花 compute 的方式分开了:一种是在固定 下喂更多 tokens,另一种是在固定 data 下激活更多参数。
图 3b 这样读。 横轴是 ,纵轴是 BPC。蓝色曲线是同一 total training compute 下的 2B MoE family。气泡大小仍然表示在这个 fixed-compute budget 下每个 MoE 实际消耗了多少 tokens。黑色水平线是 same-compute 2B Dense baseline,红色点划线是使用更多 compute 和更多 data 训练的更强 Dense baseline。
Findings.
- 固定 时,多喂 tokens 会稳定改善 BPC,这符合常见的 data-scaling 直觉。但当 training tokens 和 total parameters 固定,training compute 只是因为 MoE 激活更多参数而增加时,BPC-compute 关系不再落在同一条平滑 scaling curve 上。这说明 optimal activation region 是可能存在的。
- 在 fixed total parameters 和 fixed compute 下,MoE 不是越稀疏越好。真正有效的是一个中等稀疏度区间,大致在 10%-30%,2B 上最清楚的点在 附近。
7. Step 3:Data reuse, 7B validation, and downstream value
7.1 Step3A:3B activation-rate search under data reuse
3B 实验是对 data reuse 的第一层压力测试。它基本固定 total parameters 和 training compute,然后比较两组 MoE family:一组 unique tokens 接近 Dense-1C data budget,另一组 unique-token budget 更大。纵轴是相对 Dense-1C baseline 的 Delta BPC,越低越好;负值表示 MoE 优于 Dense-1C。
图 4 和表 2 要一起读。图给出完整的 3B activation-rate pattern;表只看更严格的 MoE-65B 设置,也就是更直接地检验:当 unique data 基本接近 Dense-1C 时,MoE 是否仍然有竞争力。
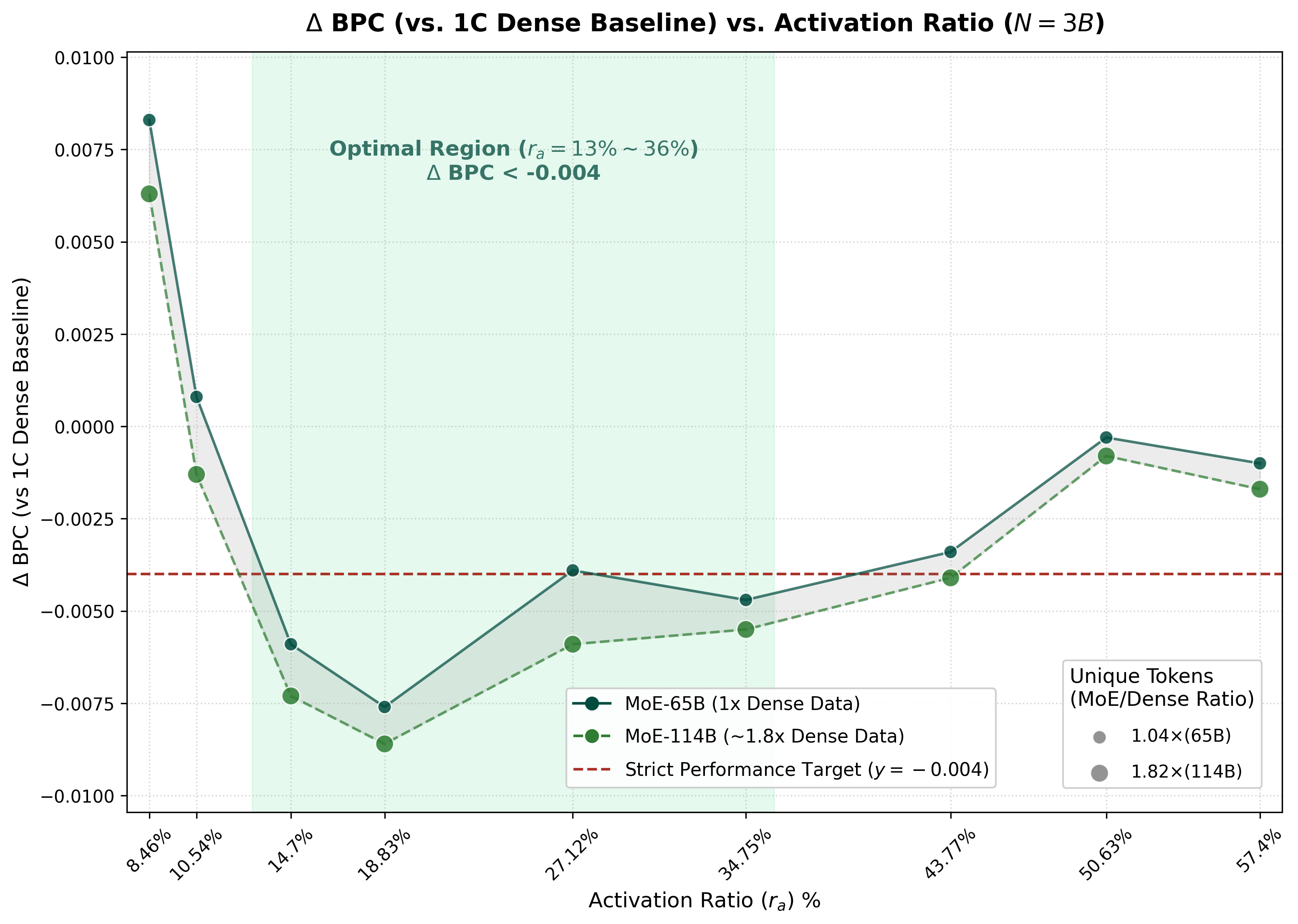
MoE-65B,unique tokens 被控制在 Dense-1C budget 附近(1.04x,约 65B tokens)。绿色虚线是 MoE-114B,unique-token budget 更宽松,约为 Dense-1C 的 1.82x。红色虚线是严格目标 Delta BPC = -0.004,阴影区域标出图中标注的 optimal region。表 2. 3B Step3A resource table。这里选出的 MoE rows 基本使用和 Dense-1C 相同的 unique-token budget,但通过 reuse 消耗更多 training tokens。BPC deltas 相对 Dense-1C 计算,越低越好。
| Model | C | ra | FLOPs/tok. | Train tok. | Unique tok. | Reuse | ΔBPC |
|---|---|---|---|---|---|---|---|
| Dense-1C baseline | 1.00x | 100.0% | 100.0% | 1.00x | 1.00x | 1.00 | 0.0000 |
| MoE-65B-Exp3 | 1.00x | 14.70% | 16.7% | 5.99x | 1.04x | 5.77 | -0.0059 |
| MoE-65B-Exp4 | 1.01x | 18.83% | 20.4% | 4.94x | 1.04x | 4.75 | -0.0076 |
| MoE-65B-Exp5 | 0.99x | 27.12% | 27.6% | 3.56x | 1.04x | 3.43 | -0.0039 |
| MoE-65B-Exp6 | 0.99x | 34.75% | 34.3% | 2.88x | 1.04x | 2.77 | -0.0047 |
关键不是“所有 reuse setting 都一样好”,而是:即使 unique tokens 几乎被压在 Dense-1C budget 附近,一个中等 activation rate 仍然可以让 MoE 在大致相同 total parameters 和 compute 下超过 Dense-1C。表里最好的点是 MoE-65B-Exp4,,Delta BPC = -0.0076。
7.2 Step3B:7B data reuse, the sweet spot, and the resource table
到 7B 时,论文换成更难的 baseline。由于这些 MoE 在 equal total parameters 和 compute 下已经超过 Dense-1C,图 5a 直接把 Dense-2C 作为 reference line。纵轴是相对 Dense-2C 的 Delta BPC;低于 0 表示 MoE 好于一个大约用 2 倍 compute 和 2 倍 unique tokens 训练的 Dense。
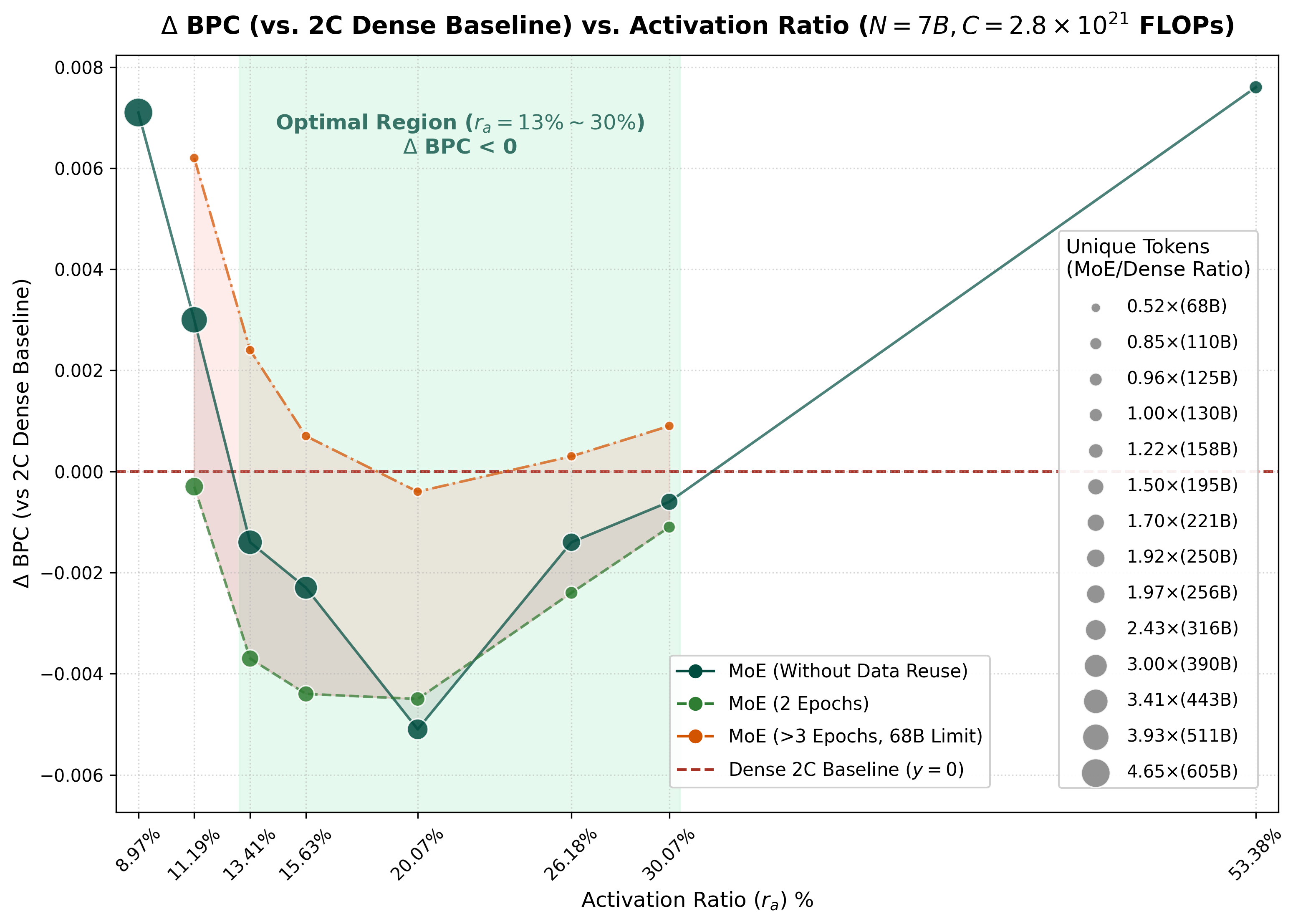
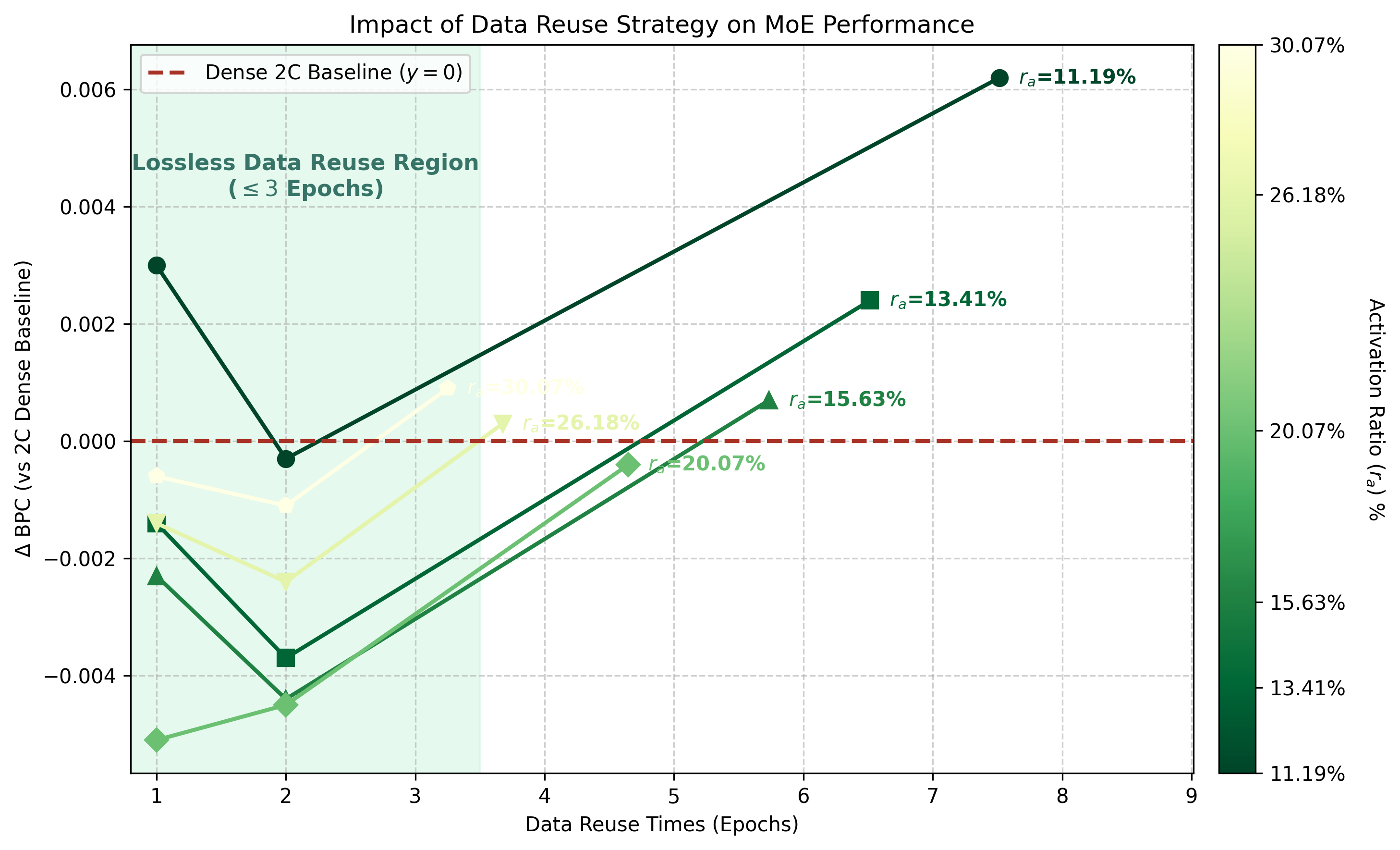
图 5a 和图 5b 从两个角度看同一组 7B trade-off。图 5a 里,不做 reuse 的 MoE 可以在较宽的中等 activation-rate 区间超过 Dense-2C,但要用多得多的 unique tokens;two epochs 后,同一区间仍然超过 Dense-2C,同时 unique data 需求明显下降;到了 strict 68B cap,大多数 activation rates 会掉队,但 仍然能对齐 Dense-2C。图 5b 则把 reuse 这个轴展开:适度 reuse 可以保留甚至提升 MoE 表现,过度 reuse 会明显退化,尤其是在 activation rate 过低时。
表 3. 7B Step3B resource table,对应图 5a 和图 5b。Deltas 相对 Dense-2C 计算;BPC 越低越好。值得注意的一行是 MoE-68B 在 :同一 total-parameter scale,68B unique tokens,4.65 reuse epochs,per-token FLOPs 只有 21.5%,BPC 0.4590,与 Dense-2C 的 0.4594 可比。这意味着,选对 activation rate 后,即使 unique tokens 被严格限制,MoE 仍然可以用更多 consumed tokens 换来 activation-rate 量级的 per-token FLOPs。
| Model / strategy | Unique tokens | Reuse epochs | FLOPs/token vs Dense | BPC | Delta BPC vs Dense-2C | |
|---|---|---|---|---|---|---|
| Dense-1C | 100.00% | 68B | 1.00 | 100.0% | 0.4736 | +0.0142 |
| Dense-2C | 100.00% | 130B | 1.00 | 100.0% | 0.4594 | 0.0000 |
| MoE-Unique | 11.19% | 511B | 1.00 | 13.3% | 0.4624 | +0.0030 |
| MoE-Unique | 13.41% | 443B | 1.00 | 15.3% | 0.4580 | -0.0014 |
| MoE-Unique | 15.63% | 390B | 1.00 | 17.4% | 0.4571 | -0.0023 |
| MoE-Unique | 20.07% | 316B | 1.00 | 21.5% | 0.4543 | -0.0051 |
| MoE-Unique | 26.18% | 250B | 1.00 | 27.2% | 0.4580 | -0.0014 |
| MoE-2Ep | 11.19% | 256B | 2.00 | 13.3% | 0.4591 | -0.0003 |
| MoE-2Ep | 13.41% | 221B | 2.00 | 15.3% | 0.4557 | -0.0037 |
| MoE-2Ep | 15.63% | 195B | 2.00 | 17.4% | 0.4550 | -0.0044 |
| MoE-2Ep | 20.07% | 158B | 2.00 | 21.5% | 0.4549 | -0.0045 |
| MoE-2Ep | 26.18% | 125B | 2.00 | 27.2% | 0.4570 | -0.0024 |
| MoE-68B | 11.19% | 68B | 7.52 | 13.3% | 0.4656 | +0.0062 |
| MoE-68B | 13.41% | 68B | 6.51 | 15.3% | 0.4618 | +0.0024 |
| MoE-68B | 15.63% | 68B | 5.74 | 17.4% | 0.4601 | +0.0007 |
| MoE-68B | 20.07% | 68B | 4.65 | 21.5% | 0.4590 | -0.0004 |
| MoE-68B | 26.18% | 68B | 3.67 | 27.2% | 0.4597 | +0.0003 |
7.3 Step3C:Downstream evaluation after SFT
Downstream 这一节的价值在于,它检查 activation-rate story 是否只是 pretraining BPC 上的现象。论文在 29 个 benchmarks 上评估 7B pre-trained 和 SFT-ed models,覆盖 reasoning、knowledge、Math、Code 等类别。Math/Code 的绝对分数需要结合附录 E 的 data-recipe 说明来读。
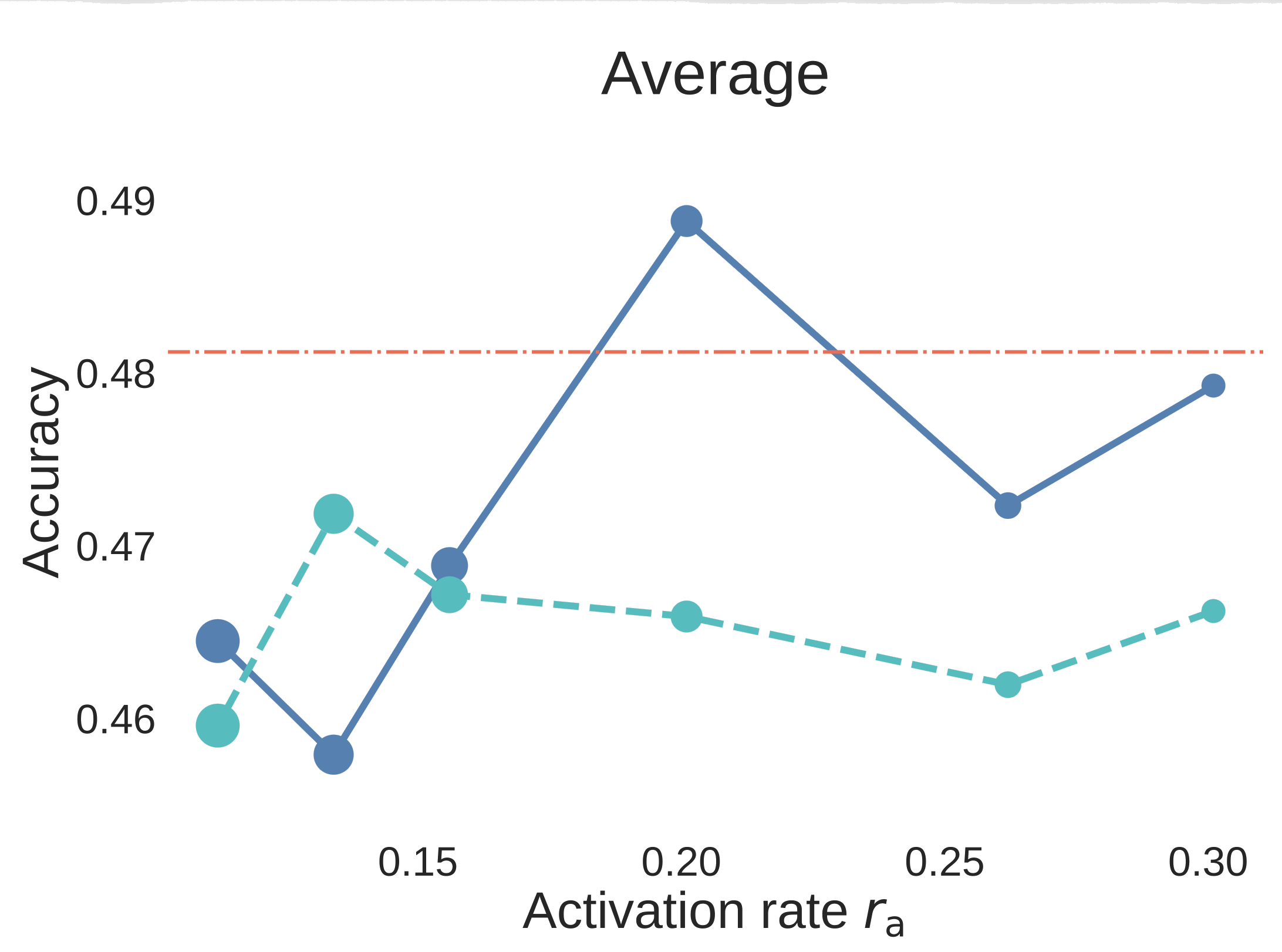
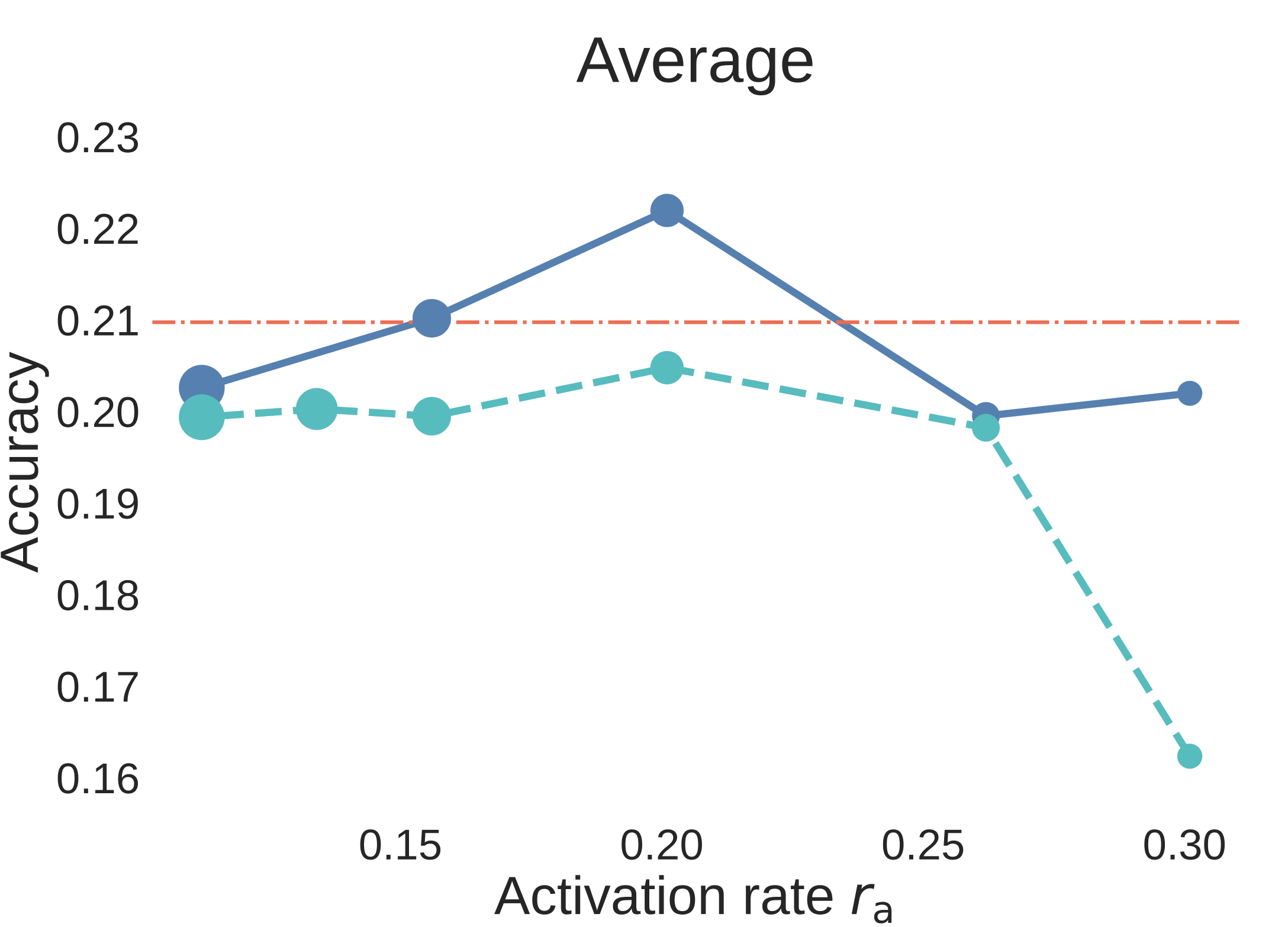
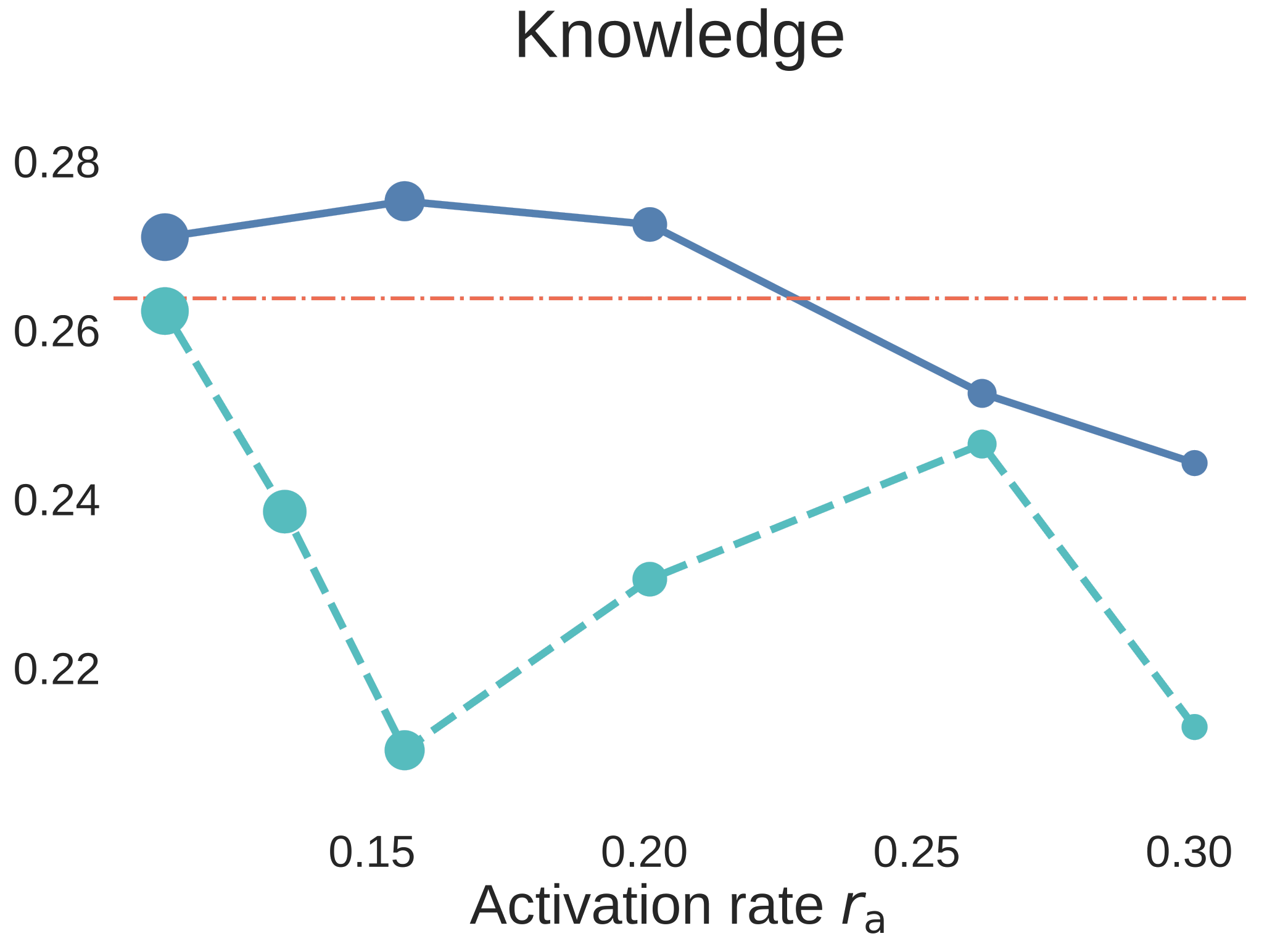
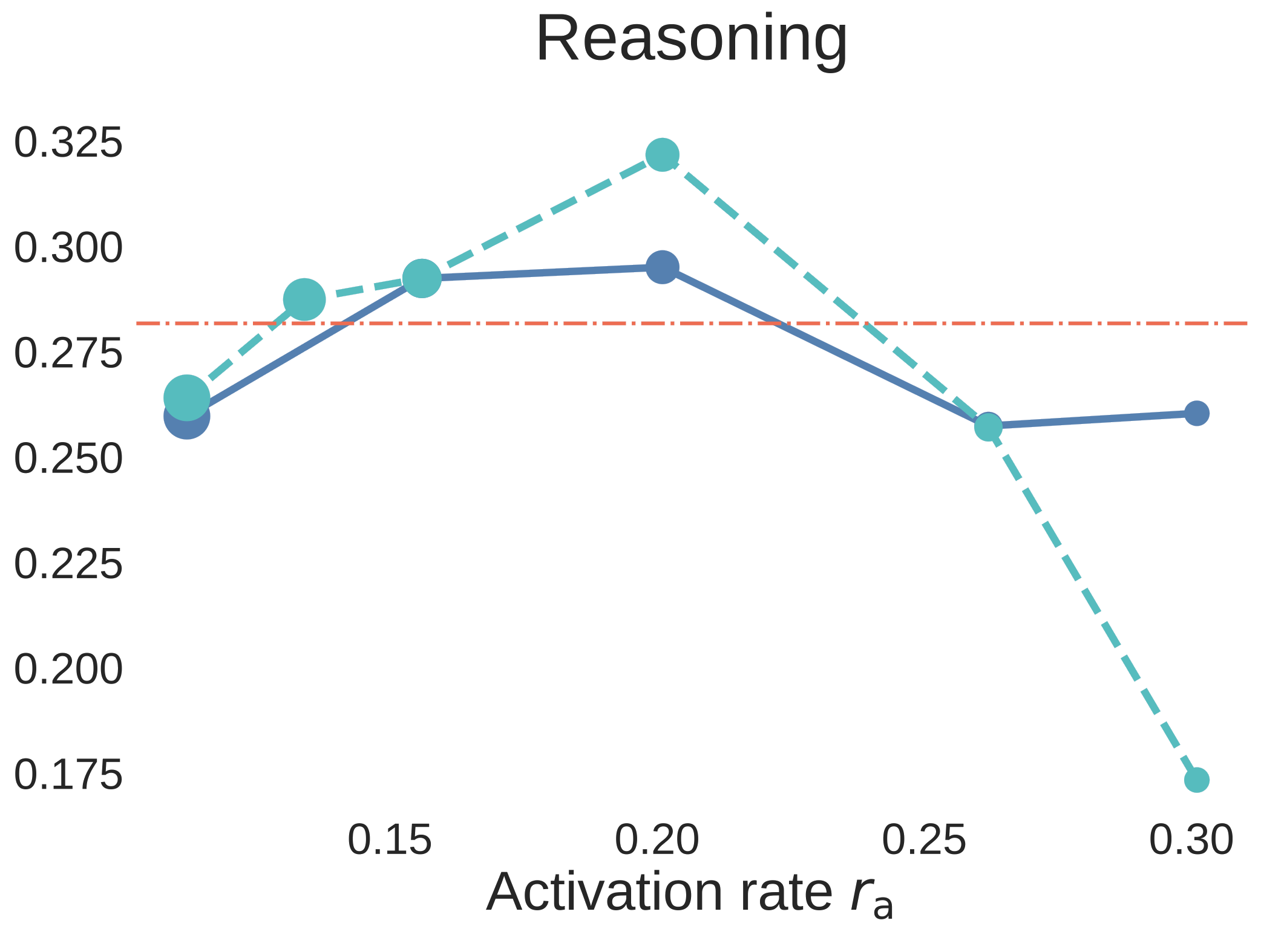
图 6. Step3C 的 7B aligned models downstream evaluation。蓝色实线使用 unique data,青色虚线使用 strict data reuse,红色点划线是 Dense-2C baseline。与 BPC 图不同,这里 accuracy 越高越好。
结果不只是“MoE 在 validation loss 上赢了”。当 时,MoE 在 SFT 后仍然很强;其中 unique-data MoE 相对 Dense 对照组的优势最清楚。Strict-reuse MoE 整体仍有竞争力,并且在 reasoning 上尤其强;但 downstream curves 也暴露出一个重要的 capability split:data reuse 对 reasoning 的影响相对小,而 unique tokens 减少时,knowledge-oriented benchmarks 更容易退化。换句话说,对于 MoE,重复数据可以强化 reasoning,但不能完全替代缺失的 world knowledge。
因此 Step3C 不只是一个附带验证。它说明 activation-rate sweet spot 对 aligned models 也有意义,同时也说明 data reuse 更适合用在什么地方:reasoning 更能承受,knowledge coverage 更敏感。
8. Practical recipe and final takeaway
对训练 SOTA MoE LLM 的团队来说,这篇论文给出的不是一句“做稀疏化”,而是一套更具体的 guidance。
- It can surpass Dense with same total parameters. 在相同的总参数量和训练计算量的情况下,MoE模型可以打平甚至超越Dense LLM。这个意味着真正第一性的东西是训练时的计算量,当训练计算量一致时,MoE引入的稀疏化并没有架构层面的劣势。
- The fundamental trade-off. 在这个情况下,MoE 用更高的 consumed-token demand 换取大幅 per-token FLOPs reduction。例如,当 时,资源方程意味着需要大约 consumed tokens;7B sweet-spot 只有 Dense 的
21.5%per-token FLOPs,也就是在相同 total-parameter footprint 下约5x的 inference-side FLOPs reduction。 - Scale-aware optimal sparsity. “Sparser is better” 是错觉。本文 2B、3B、7B sweeps 里,有效 activation-rate region 不窄,但也不是任意的:大致在 10%-30%,当时这个最优activation-rate region 可能随着模型尺寸最大像更加稀疏的方向扩展或者偏移。
- Data reuse works, within limits. 当 unique data 有限时,multi-epoch reuse 可以保住 MoE advantage。例如,在 7B sweep 里,moderate reuse window 仍然有效;同时reasoning 相对更能承受 repeated data,而 knowledge coverage 对Unique Token更敏感。
假设我们想训练一个 1T-total-parameter 的 MoE model。作为对比,一个 1T Dense model 按 Chinchilla 需要约 20T tokens。如果这个 MoE 选择 100B active parameters,也就是 10% activation rate,那么要以 Dense-level performance 为目标,就应该为约 200T consumed tokens 做预算。如果 unique data 不够,moderate multi-epoch reuse 可以帮忙。
这篇 Paper 对于想训练 frontier model 的团队的启发在于:它把 MoE scaling 从一句含糊的 “sparse is efficient”,落成一个资源配方:选择合适的 activation rate,采用更加激进的 data scaling 策略;当 unique tokens 不够时,可以适度使用 data reuse,例如控制在大约 3 epochs 以内。
评论
评论由 GitHub Discussions 托管。登录 GitHub 后即可参与讨论。