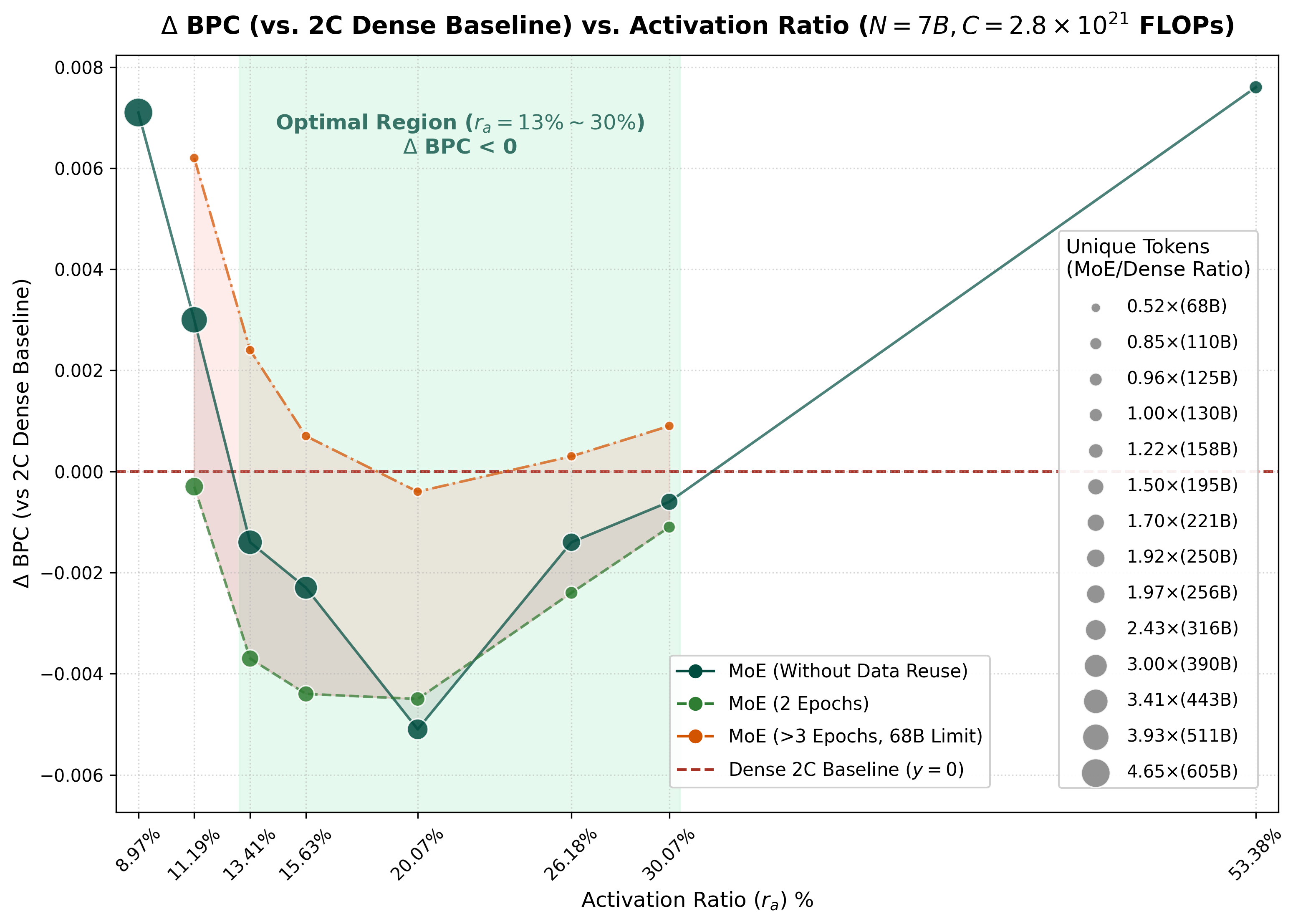
Can We Train an MoE Model with the Same Total Parameters and Performance as Dense?
An ICLR 2026 Oral paper explainer: MoE needs a more aggressive data scaling strategy.
MoEPretrainLLMICLR 2026 oralData ScalingData Reuse
Paper explainers and research notes for my own work.
An ICLR 2026 Oral paper explainer: MoE needs a more aggressive data scaling strategy.
An ICLR 2026 Oral paper explainer: MoE needs a more aggressive data scaling strategy.
Choose another topic or return to the full research flow.